Distributed VCS: Git, Mercurial.
Centralized VCS: CVS, Perforce, SVN, TFS
The main difference between the two classes is that Centralized VCSs keep the history of changes on a central server from which everyone requests the latest version of the work and pushes the latest changes to. This means that everyone sharing the server also shares everyone's work.
On the other hand, on a Distributed VCS, everyone has a local copy of the entire work's history. This means that it is not necessary to be online to change revisions or add changes to the work. "Distributed" comes from the fact that there isn't a central entity in charge of the work's history, so that anyone can sync with any other team member. This helps avoid failure due to a crash of the central versioning server.
This blog is about the key concepts and commands of git (github is used as remote repository) :
Commands :
git clone -- Clones the remote repository to local system
git status -- to get the status of the repository. Gives branch details
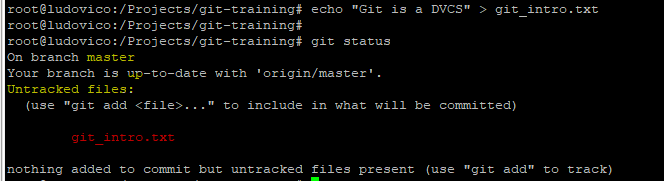
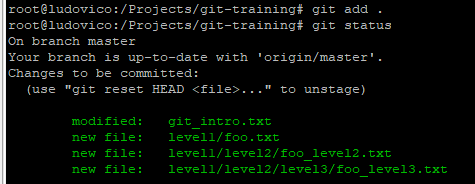
Adding a file to the working directory and checking the status
Untracked files - files existing in working directory and not yet added to git
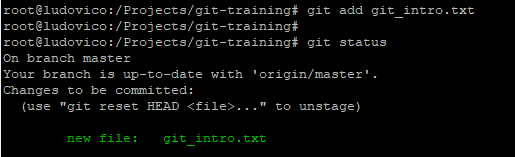
Adding the file to Staging Area and checking the status
Commiting the File and Checking the status
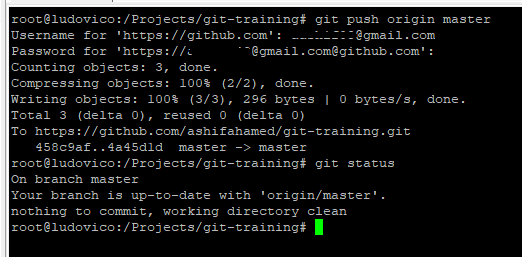
Pushing the changes to Remote repository (github) and checking the status
git push origin master
origin - remote reference
master - branch name
Tracked and Untracked Files
Each file in your working directory can be in one of two states: tracked or untracked.
Tracked files are files that were in the last snapshot; they can be unmodified, modified, or staged. In short, tracked files are files that Git knows about.
git ls-files -- gives the list of tracked files
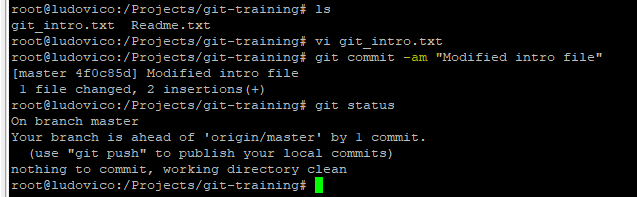
Any changes to the tracked files are directly committed like below : (without adding it to staging area)
git commit -am "comments"
Eg:
Untracked files are everything else — any files in your working directory that were not in your last snapshot and are not in your staging area. When you first clone a repository, all of your files will be tracked and unmodified because Git just checked them out and you haven't edited anything.
Recursive add - adds the files under subdirectories to staging area recursively
git add .
Backing Out Changes from the staging area and rolling back to previous commit
"git reset HEAD <file>..." to unstage - is the command used to unstage / remove the files from staging area to working directory . 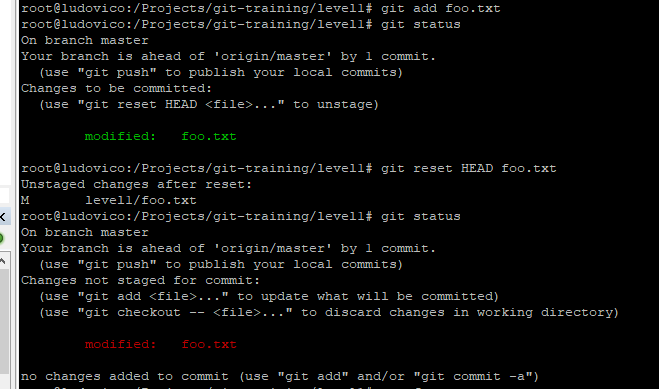
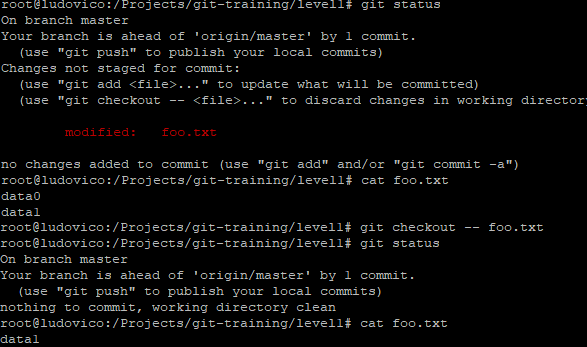
Roll backing the changes on working directory to previous commit
git checkout -- <file> -- to discard changes in working directory
Commit History of a file :
git log --follow <file_name>
git show <commit_id>
Displaying all the commits:
git log --all --graph --decorate --oneline
Git Alias
Git doesn't automatically infer your command if you type it in partially. If you don't want to type the entire text of each of the Git commands, you can easily set up an alias for each command using
git config.
Here are a couple of examples you may want to set up:
$ git config --global alias.hist "log --all --graph --decorate --oneline"
This alias is stored in the file named "config" of .git directory
Ignoring Files
Files that you don't want Git to automatically add or even show you as being untracked. These are generally automatically generated files such as log files or files produced by your build system. In such cases, you can create a file listing patterns to match them named .gitignore. Here is an example .gitignore file:
$ cat .gitignore
*.[oa]
*~
The first line tells Git to ignore any files ending in ".o" or ".a" — object and archive files that may be the product of building your code. The second line tells Git to ignore all files whose names end with a tilde (~), which is used by many text editors such as Emacs to mark temporary files. You may alsoinclude a log, tmp, or pid directory; automatically generated documentation; and so on. Setting up a .gitignore file for your new repository before you get going is generally a good .idea so you don't accidentally commit files that you really don't want in your Git repository
Remote Repository Reference
root@ludovico:/Projects/git-training# git remote
origin
root@ludovico:/Projects/git-training# git remote show origin
* remote origin
HEAD branch: master
Remote branch:
master tracked
Local branch configured for 'git pull':
master merges with remote master
Local ref configured for 'git push':
master pushes to master (fast-forwardable)
Configuration of External Diff and Merge tools :
My selection of external tool is P4Merge from Perforce. Post installation of P4Merge and its mandatory to do below configuration change in git .
git config --global merge.tool p4merge
git config --global mergetool.p4merge.path "C:\Program Files\Perforce\p4merge.exe"
git config --global diff.tool p4merge
git config --global difftool.p4merge.path "C:\Program Files\Perforce\p4merge.exe"
Comparison
Working Directory Vs Staging Area
git diff
git difftool (In case of p4merge, staging area on left side and working directory on the right)
Working Directory Vs Last Commit
git diff HEAD
git difftool HEAD (In case of p4merge, HEAD/Last Commit on left side and working directory on the right)
Staging Area vs Last Commit
git diff --staged HEAD
git difftool --staged HEAD (In case of p4merge, HEAD/Last Commit on left side and staging area on the right)
Note: These commands give details about all files that are different between the source and target. If you want to compare particular , mention the path i.e git diff -- foo.txt
Branching :
git branch -- lists all the local branches (branch name with * is the current branch )
git branch -a -- lists both remote and local branches
git branch <branch_name> -- creates the new branch
git checkout <branch_name> -- checkout is used to switch from one branch to other
Creation of new branch and switching to the newly created branch is done by using below command:
git checkout -b <branch_name>
Merge conflict :
Can be resolved by using mergetool / manually .